
UVa 11572 contains a story about a magic snowflake-capturing machine, but the underlying puzzle can be stated quite simply:
Given a sequence of integers, find the length of the longest contiguous subsequence containing no repeated elements.
The sequence given in the sample input is:
1, 2, 3, 2, 1
The subsequence 1, 2, 3, 2 (length=4) does not meet the criteria, since the element 2 is repeated. However, 1, 2, 3 (length=3) does, as does 3, 2, 1. Since there isn’t a longer subsequence that meets the criteria, the correct answer to the sample problem is 3.
The Brute Force Approach
uHunt recommends using the C++ STL map or the Java equivalent TreeMap to solve this problem. Like a hash table, these data structures implement an efficient way to associate keys and values. But unlike a hash table, they are somewhat slower: $O(\log n)$ vs. $O(1)$ in the average case for operations like get and put. In exchange for slower performance, they provide extra functionality, such as being able to efficiently remove the value with the lowest key, or iterate through their contents in sorted order.
To solve UVa 11572 in $O(n^2)$ time, we don’t actually need that extra map functionality. We can just use a hash table to check every possible subsequence:
for each integer in the input sequence
create a new hash table
current_subsequence_length = 0
while the table does not contain the current integer
add integer to table
increment current_subsequence_length
move to the next integer
update max_subsequence_length
print max_subsequence_length
Starting at every input position, this algorithm builds a sequence by adding consecutive input values until it finds a duplicate integer. The length of the longest sequence built in such a way is the answer.
This approach may clarify what the problem is looking for. But since $n$ can be as high as $10^6$ for this problem, an $O(n^2)$ solution is not feasible. We need a more efficient approach.
Key Idea #1: Segments
Finding a solution that runs faster than $O(n^2)$ is tricky, so let’s take it one step at a time.
Define a segment for an input integer x as a contiguous subsequence that begins with x and ends at the next occurrence of x. For example, in the sample input above, 2, 3, 2 is a segment for the integer 2 in that input sequence.
For any starting position p in a sequence, the longest contiguous subsequence that could satisfy this problem’s requirements is one less than the length of the segment beginning at p. For example, in the sample input, there is a five-element segment 1, 2, 3, 2, 1 that begins and ends with 1. Looking only at the endpoints of this segment, we know that the 1 repeats for the first time at position 4. Since our answer is not allowed to have any repeated elements, the maximum length is four.
However, four clearly can’t be our final answer, since there is a repeated 2 inside the segment. So the next question is how we can use the idea of segments to find not just the maximum possible length, but the maximum length that meets the problem requirements.
Key Idea #2: Segments Within Segments
Here’s a visual representation of the sample input, divided into segments.
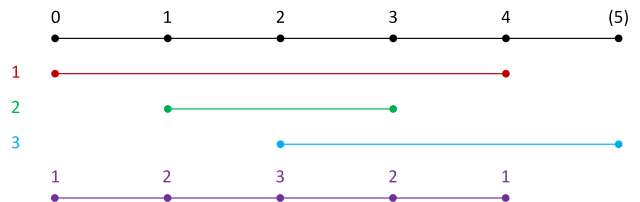
Read the diagram as follows:
- The black line at the top shows zero-based positions in the full sequence. Positions 0 through 4 contain the sequence elements. Position (5) is a sentinel position, which I’ll explain later.
- The red line shows the segment from position 0 to position 4 that begins and ends with
1. - The green line shows the segment from position 1 to position 3 that begins and ends with
2. - The blue line shows the segment from position 2 to position (5). This is where the sentinel position comes in. Since there is only one
3in the sequence, there is no end position to the segment that starts with3. The sentinel position ensures that every segment has an endpoint. This will be useful in the algorithm described below. - The purple line at the bottom shows the input integer at each position.
Notice that the segments start at consecutive positions starting with position 0 as we move from the top to the bottom of the diagram. This is also important for the algorithm.
Here’s the rule we need to use, using the idea of segments within segments:
For the segment at each position in the original sequence, find the contained segment with the lowest endpoint.
Notice that the green segment (2) in the diagram is contained within the red segment (1). The blue segment (3) is not contained in any segment, since its (virtual) endpoint is beyond the range of the original sequence. Therefore, if we are evaluating the red segment, we have to stop before position 3, the endpoint of the green segment. Otherwise we’ll end up with a duplicate 2 value. Stopping one position before the end of the green segment gives us a total subsequence length of 3. The subsequence is 1, 2, 3.
Why does this rule work? As I mentioned earlier, the segments are sorted by starting position. If we move along the red segment, we build up a sequence with a new integer at each position: 1 (the start of the red segment), 2 (the start of the green segment), and 3 (the start of the blue segment). At position 3, the green segment ends, which due to the way we defined segments means that we have a duplicate integer. Since this isn’t allowed by the rules, this is as far as we can go from the start position. We started at position 0 and stopped before position 3, so our subsequence length is 3 - 0 = 3.
The green segment doesn’t contain any sub-segments, so we can calculate its subsequence length just by subtracting its end position from its start position: 3 - 1 = 2. The subsequence is 2, 3.
The blue segment also doesn’t contain any sub-segments, so its subsequence length is 5 - 2 = 3. The subsequence is 3, 2, 1. Notice that the sentinel at position 5 is useful for calculating the length of segments that only have a start position. In fact, we’ll see in the full algorithm that every integer in the sequence will have a segment that ends at position n, where n is the length of the input sequence.
The Algorithm
Using the two key ideas of segments and segments within segments, we can develop an efficient algorithm to find the length of the longest contiguous subsequence containing no repeated elements.
The algorithm uses two passes, one for each key idea:
- Pass #1: Construct the segments.
- Pass #2: For each segment from pass #1, find the contained sub-segment that ends first.
These data structures are used to store intermediate results:
- A
HashMapthat maps an integer to the input position where it was last seen. - A
Segmenttype, which is an ordered pair of integers identifying the start and end positions for a segment. - Two arrays of
Segment, one indexed by starting position and the other indexed by ending position. These allow us to look up any segments by its starting or ending position, in constant time.
It turns out that a map / TreeMap is not actually required for this algorithm with the constraints as specified. The problem statement guarantees that the input will contain no more than $10^6$ integers. This is a small enough number that we can allocate two arrays of that size without violating any memory limits. The integers themselves, however, are in the range of 0 to $10^9$. The online judge won’t provide enough heap space to allocate an array that large, so we can’t index an array by input integer value. But since we don’t need to keep the integers sorted, we can use a HashMap, which still gives us $O(1)$ insertion and retrieval performance.
Pass #1: Construct the Segments
The algorithm requires that we look up segment end positions as we go through the input. At the point where we need a segment end position, we won’t yet have reached that position in reading the input. Therefore, we need to construct all of the segments in advance. That’s the purpose of Pass #1.
Here’s the pseudocode:
create a HashMap called snowflakePosition
create an array of Segment called segmentsByStart
create an array of Segment called segmentsByEnd
for each input integer i
look up the previous position of i in snowflakePosition
store the current position of i in snowflakePosition
if there was no previous position, continue with the next i
otherwise, create a segment using the previous and current positions
store the segment in segmentsByStart, indexed by previous position
store the same segment in segmentsByEnd, indexed by current position
Since our algorithm makes one pass through each of the $n$ input integers, and HashMap and array operations are both $O(1)$, we can create these segment arrays in $O(n)$ time.
Using these two arrays of Segment, we can now find the segment that begins or ends at any position in the input. We’ll use this in pass #2.
Pass #2: Find the Longest Sequence
In Pass #2, we’ll use the Segment arrays to find the length of the longest contiguous subsequence containing no repeated elements, as follows:
for each input position p (where p is in the range 0..n-1)
using segmentsByStart, retrieve the segment s1 that starts at p
if s1 is null (no segment found)
create two segments that both start at p and end at n
else
remove s1 from segmentsByEnd (by setting it to null)
set len to the length of s1
find s2, the next non-null endpoint in segmentsByEnd
if s2 is contained in s1
recalculate len as the distance from s1.start to s2.end
if len is the longest length found so far, save it
write the value of the longest len found
Pass #2 is a bit more complex than Pass #1, so here are some key points:
- The last occurrence of every unique integer in the sequence starts a segment that ends at position $n$. Rather than spending time in Pass #1 creating all of these, we can just create them on the fly when we find a
nullinsegmentsByStart. That’s the purpose of theif s1 is nullcheck, and it corresponds to the concept of the sentinel position explained earlier. - Whenever we retrieve a segment from
segmentsByStart, we remove it fromsegmentsByEnd. This simplifies our search fors2, the segment with the smallest endpoint: If we iterate throughsegmentsByEndin order, we can stop at the first non-null entry. - You can think of both
segmentsByStartandsegmentsByEndas priority queues, since we’re using them to retrieve the segment with the smallest start point or the smallest endpoint, respectively. Since every position in the input set is occupied by a number, the segment arrays are dense. This makes it efficient to use arrays rather than trees to implement these priority queues.
To evaluate the performance of Pass #2, consider that we need to iterate through two arrays, segmentsByStart and segmentsByEnd, both of which have size n. Each iteration of the main loop in pass #2 advances the segmentsByStart index by exactly one position. During that iteration, we may advance the segmentsByEnd index by one or more positions, or we may not advance it at all (if the current s1 doesn’t completely contain the current s2). But we never backtrack in either array. Therefore, we make exactly one pass through each array, and since array and map operations are both $O(1)$, we can complete Pass #2 in $O(n)$ time.
Since Pass #1 also runs in $O(n)$ time, the entire algorithm runs in $O(n)$ time. My Java submission ran in 0.866 seconds on UVa OJ, which at the time got me a rank of 899 for this problem. That’s a lot slower than the best C++ implementation (0.068 seconds), but it gets the job done in less than half of the time limit.
Thoughts on Solving UVa 11572
Solving UVa 11572 involves some conceptual challenges and some implementation challenges. The first concept to come up with is considering the input sequence as a set of pairs of matching integers. It might seem that the first item in each pair starts a sequence of unique integers, and the second one ends it. But that’s not quite right, since these segments can overlap. So we really want to think about each segment and all of the segments that are completely contained within it. The contained segment that ends first inside the parent segment is the one that ends the sequence, since it introduces the first duplicate integer to the sequence.
There’s no simple process to come up with this concept of segments, or key concepts in other programs. It’s mainly a matter of playing around with sample data, and not starting to write code too soon. Nevertheless, I still ended up writing some code that I later discarded as I was optimizing my solution to fit within the time limit.
With those conceptual details in mind, we can think about implementation. Since we need to know where the end of the parent segment is before we actually get to the end of it, we have to make an initial pass through the input before doing the main processing. That raises the question of how to store the segment information. The hint for this problem in CP3 suggests using a map to associate position with snowflake size, which it says leads to an $O(n \log n)$ solution. I didn’t investigate that solution. However, I did run into some performance challenges with the $O(\log n)$ performance of the Java TreeMap, which led me to choose the HashMap and array approach, and the corresponding $O(n)$ solution. When using Java for UVa OJ solutions, it’s possible that even a fairly fast $O(n \log n)$ solution may not be fast enough.
To help optimize performance in my Java solution for this problem, I used VisualVM, which identified the TreeMap bottleneck. I was able to get a passing solution with one array and one TreeMap, but I eventually settled on just using two arrays. As I mentioned in the VisualVM article, it’s not always possible to profile your way to a passing solution. In this case, my algorithm design was fast enough in theory, but needed some data structure adjustments to fit within the low two-second limit given Java’s performance challenges for short-duration programs.
(Image credit: Alexey Kljatov)