I’m working on a project this year to build a competitive programming FAQ. This is one in a series of articles describing the research, writing, and tool creation process. To read the whole series, see my CPFAQ category page.
To organize my list of Quora questions, I have started giving each one a primary category that indicates what it is primarily about. For example, the primary category for How can I sharpen my mathematical skills in the context of competitive programming? is Mathematics (with Competitive Programming as the implicit overall topic for all questions).
On Quora, categories are known as topics, and they are assigned to questions by (1) Quora users, and (2) the Quora Topic Bot (QTB), an automated process. But there’s a lot of inaccuracy in topic assignments. For topics assigned by users, there are a few contributors to inaccuracy: First, most question askers don’t think much about correct topic assignment. They are just trying to get their question answered. Secondly, they often just spam the question with as many topics as possible because they think it will increase the probability of it being answered. For topics assigned by QTB, the main problem is that machine learning algorithms still aren’t perfect at assigning topics, and they can be misled by users’ topic assignment behavior.
Using a set of Quora questions that I categorized myself, I thought it would be interesting to see what kind of auto-categorization results I could get using some free text classifiers.
Document Classification
Document classification, or text classification, is the general term for what I described above. More specifically, I’m looking at supervised automatic document classification, where the document is a Quora question title, automatic means I’m using a classification algorithm, and supervised means I’ll be telling the algorithm what the classification should be for some questions, and then seeing how it performs on other questions.
There are many tools that do automated document classification. I tried out two of them, one commercial and one open-source.
MonkeyLearn
MonkeyLearn is a commercial online machine learning system that provides customer classifiers that can be trained with user data.
Creating a classifier using MonkeyLearn is a fairly simple process. To train the classifier on my Quora question data, I used their manual training process: I uploaded my list of about 500 questions, and then the system prompted me to associate one or more categories with each question. After a few rounds of categorization, the classifier started to suggest categories for each question, which I could accept or modify. When I finished categorizing about 70 questions, the system said the classifier was sufficiently trained and I could either test it or keep classifying.
Even with only a few questions classified, the system started to make some good recommendations. Here are some of its results using a training set of 70 questions:
- How should you prepare for Google Code Jam? (Contests)
- How does one start with TopCoder? (Getting Started)
- What are the standard puzzles asked in programming interviews? (Interviews and Jobs)
However, the classifier can only work with the data it has been trained with. Here are some examples where the training data seems to be misleading it:
- What is it like to win IOI? (classified as Problems; should be Contests)
- How do I progress from blue to yellow on TopCoder? (classified as Problems; should be Getting Better or Online Judges)
- What should I do to improve my CodeForces rating? (classified as Interviews and Jobs; should be Getting Better or Online Judges)
Despite promising early results, the main problem with MonkeyLearn for my project is cost. For the free account plan, classification is limited to 300 queries per month and the classifier can only have 300 texts. With these restrictions, I would barely be able to get started classifying my master question list of 16.5k questions.
Increasing the query allotment and model size requires a paid plan. But the lowest paid MonkeyLearn tier is $299 per month, so it’s clearly targeted only at businesses that somehow derive income from document classification.
TextBlob
To avoid the restrictions of a commercial web service, I tried out an open-source text processing system called TextBlob, which I ran on my local machine. Using a simple classification tutorial from the TextBlob documentation, I was able to quickly import my entire list of 500 manually-classified questions (in TSV format) using the following Python commands:
from textblob.classifiers import NaiveBayesClassifier
with open('train.tsv', 'r', encoding='utf8') as fp:
cl = NaiveBayesClassifier(fp, format="tsv")
The classifier can then be called to classify any input text. For example:
>>> cl.classify("What are some good ways to approach
a dynamic programming question?")
'Algorithms and data structures'
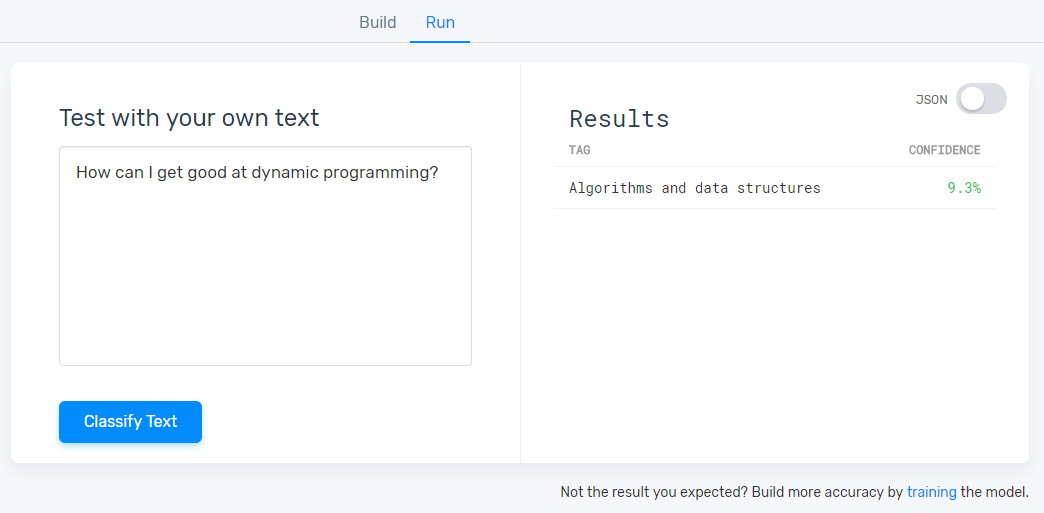
One interesting test result is that the classifier doesn’t always product the correct classification even when it is given the exact text that was used to train it, since it relies on the training set as a whole. For example, I manually classified “How can I get good at dynamic programming?” as “Algorithms and data structures.” But the classifier classified it as “Interviews and Jobs.” Since I classified dynamic programming-related questions in multiple categories depending on the context (e.g., “What are the top 10 most popular dynamic programming problems among interviewers?” –> “Interview and Jobs”), the classifier presumably found the question more similar to Interviews and Jobs questions than to Algorithms and data structures questions.
When I ran the classifier on my entire training set, it attained 69.5% accuracy when compared with the training data. Since I used 20 categories, this is much better than random chance. But it would still require manual fixing if I wanted to use the output directly for CPFAQ. It will be interesting to see how much additional training is required to get the accuracy into the >90% range. One possibility to increase accuracy is to include answer text in the training set. This would provide much more text for the classifier to work with.
Due to the limitations of the free MonkeyLearn plan, I can’t run a similar test on my entire training set. However, for the single example question discussed above, MonkeyLearn did correctly classify it as Algorithms and data structures.
Next Steps
Text classification is a big area of study that I don’t want to get sidetracked with. However, the TextBlob results are promising enough after a minimal time investment that I may continue testing it with manual training data to see how its accuracy improves.